BigQuery Cheat Sheet
Use this cheat sheet to quickly reference some of the most common Google BigQuery commands, expressions, data types, and more.


About Google BigQuery
Google BigQuery is a fully managed data warehouse with advanced functionality and pre-built features like machine learning, geospatial analysis, and business intelligence tooling.
BigQuery’s scalable, distributed analysis engine allows for hyper-efficient querying and data manipulation. Given its serverless architecture and self-managed implementation, little warehouse infrastructure and resource management are required.
BigQuery stores data using a columnar format, optimized for analytical queries and compatible with database transaction semantics (ACID). Additionally, BigQuery provides centralized management of all data and compute resources, secured through Google’s Identity and Access Management (IAM), which provides secure, yet flexible, security management (regardless of whether you're following Google’s best practices or taking a more granular approach).
Learn More
Initializing BigQuery Resources With DDL
These are common data definition language (DDL) statements for creating and modifying BigQuery resources. DDL statements can be run using the Cloud Console, Google’s bq command-line tool, or through other BigQuery client APIs.
Creating Schemas
CREATE SCHEMA [ IF NOT EXISTS ]
[project_name.]dataset_name
[OPTIONS(schema_option_list)]
Creating Tables
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] TABLE [ IF NOT EXISTS ]
table_name
[(
column[, ...]
)]
[PARTITION BY partition_expression]
[CLUSTER BY clustering_column_list]
[OPTIONS(table_option_list)]
[AS query_statement]
Creating Views
CREATE [ OR REPLACE ] VIEW [ IF NOT EXISTS ] view_name
[(view_column_name_list)]
[OPTIONS(view_option_list)]
AS query_expression
Creating Materialized Views
CREATE [ OR REPLACE ] MATERIALIZED VIEW [ IF NOT EXISTS ] materialized_view_name
[PARTITION BY partition_expression]
[CLUSTER BY clustering_column_list
[OPTIONS(materialized_view_option_list)]
AS query_expression

Altering Schemas
Dropping Schemas
DROP SCHEMA [IF EXISTS]
[project_name.]dataset_name
[ CASCADE | RESTRICT ]

Altering Tables
Adding Columns
ALTER TABLE table_name
ADD COLUMN [IF NOT EXISTS] column_name column_schema [, ...]
Dropping Columns
ALTER TABLE table_name
DROP COLUMN [IF EXISTS] column_name [, ...]
Dropping Tables
DROP TABLE [IF EXISTS] table_name
Renaming Tables
ALTER TABLE [IF EXISTS] table_name
RENAME TO new_table_name
Setting Data Types
ALTER TABLE [IF EXISTS] table_name
ALTER COLUMN [IF EXISTS] column_name SET DATA TYPE data_type

Altering Views
Dropping Views
DROP VIEW [IF EXISTS] view_name
Altering Materialized Views
Dropping Materialized Views
DROP MATERIALIZED VIEW [IF EXISTS] mv_name

BigQuery Data Types
Here’s a short overview of all Google standard SQL data types with information about their value parameters. BigQuery is unique in its frequent use of ARRAY and STRUCT data types, as well as its geospatial analysis features leveraging JSON. For more context on Google BigQuery data types, check out the BigQuery Docs.
Array Type
An ordered list of zero or more elements of non-ARRAY values. Each element in an array must be of the same type. BigQuery does not allow ARRAYs of ARRAYs. Arrays are declared as: ARRAY<T>
Boolean Type
Values represented by the keywords TRUE or FALSE, providing logical operations on data. Boolean values are sorted in the following order NULL, FALSE, TRUE, from least to greatest.
Bytes Type
BYTES are variable-length binary data. STRING and BYTES can not be used interchangeably, however most functions on STRING are also defined on BYTES.
Date Type
A type representing a logical calendar date, which is independent of time zone. A DATE does not represent a 24-hour time period, since time periods may differ across time zones. A DATE may also be shorter or longer during daylight savings time.
JSON Type
Represents JSON data, a data-interchange format. Google BigQuery makes several assumptions when creating JSON data:
- Exact preservation of booleans, strings, and nulls
- Whitespace characters are not preserved
- Integers within the range -9,223,372,036,854,775,808 (minimal signed 64-bit integer) to 18,446,744,073,709,551,615 (maximal unsigned 64-bit integer) and floating point numbers within a domain of FLOAT64 (see 'Numeric Types' below).
- Element order is preserved exactly
- If duplicate keys are provided, only the first key is preserved
- Up to 100 levels can be nested
- The format of the original string representation of a JSON number may not be preserved
Numeric Types
Integer Type
Numeric values that do not have fractional components ranging from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. Represented as INT64.
Decimal Type
Numeric values with fixed decimal precision and scale, where precision is the number of digits in a number. Scale is how many digits appear after the decimal point. Provides exact representation of fractions. Represented as NUMERIC. Precision, scale & range are:
Precision: 38
Scale: 9
Min: -9.9999999999999999999999999999999999999E+28
Max: 9.9999999999999999999999999999999999999E+28
FLOAT64 Type
Floating point values are approximate numeric values with fractional components. Represented by FLOAT64.
String Type
Variable-length character (Unicode) data. BigQuery only accepts UTF-8 encoded strings. All output strings will be UTF-8 encoded as well. Represented as STRING.
Struct Type
A BigQuery STRUCT is a container of ordered fields, each with a type and field name. A struct is declared as: STRUCT <T>
The elements of a STRUCT can be arbitrarily complex... e.g. nested structs, structs containing arrays, or structs of single values are all valid.
Timestamp Type
A TIMESTAMP object represents an absolute point in time, independent of time zone or time convention, like Daylight Savings Time. TIMESTAMPs have nanosecond precision and can be converted to DATE objects quite easily. TIMESTAMPs are formatted as...
YYYY-[M]M-[D]D[( |T)[H]H:[M]M:[S]S[.F]][time zone]
Adding & Editing BigQuery Data
Once tables are defined, we can insert, update, and select from them via queries. Here are common queries in BigQuery-friendly syntax for interacting with data using standard SQL data manipulation language (DML).
Selecting Data
SELECT [ expression. ]* FROM table_name
Inserting New Data
INSERT [INTO] target_name
(column_name_1 [, ..., column_name_n] )
VALUES (row_1_column_1_expr [, ..., row_1_column_n_expr ] )
[, ..., (row_k_column_1_expr [, ..., row_k_column_n_expr ] ) ]
Updating Existing Data
UPDATE target_name [[AS] alias]
SET set_clause
[FROM from_clause]
WHERE condition
Deleting Existing Data
DELETE [FROM] target_name [alias]
WHERE condition
Truncating Tables
TRUNCATE TABLE [[project_name.]dataset_name.]table_name
Merging Data
MERGE [INTO] target_name [[AS] alias]
USING source_name
ON merge_condition
Common Queries
Here are some common SQL queries for selecting, grouping, and mutating data using BigQuery syntax.
Select All Columns From a Table
SELECT * FROM dataset_name
Find the Max of a Column
SELECT MAX(column) FROM dataset_name
Order Results
SELECT column_1, column_2 FROM dataset_name ORDER BY column_1
Truncate Results to 10 Rows
SELECT * FROM dataset_name LIMIT 10
Join Data
To join data on a common key while keeping rows without a corresponding value:
SELECT * FROM dataset_1 LEFT JOIN dataset_2 ON dataset_1.primary_key = dataset_2.dataset_1_primary_key
To join data on a common key and only keep matching rows:
SELECT * FROM dataset_1 INNER JOIN dataset_2 ON dataset_1.primary_key = dataset_2.dataset_1_primary_key
Concatenate Data
SELECT column_1, column_2 FROM dataset_1
UNION
SELECT column_1, column_2 FROM dataset_2
To only concatenate distinct rows:
SELECT column_1, column_2 FROM dataset_1
UNION DISTINCT
SELECT column_1, column_2 FROM dataset_2
Find the Max of Data By a Group
SELECT group_1, MAX(column) FROM dataset_name GROUP BY 1
Filter Data Using Where Conditions
SELECT * FROM dataset_name WHERE condition = TRUE
Beyond the Cheat Sheet
You can read more about Google BigQuery within their comprehensive documentation.
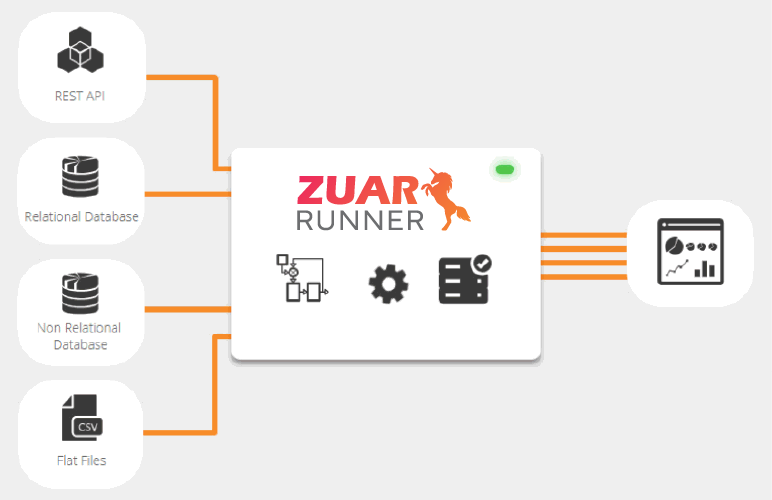
Zuar provides products and services that pave a path towards a successful data strategy. We can reduce the time and cost of implementing data projects such as BigQuery rollouts, including integrations with other systems, data prep and normalization, and analytics/dashboards.