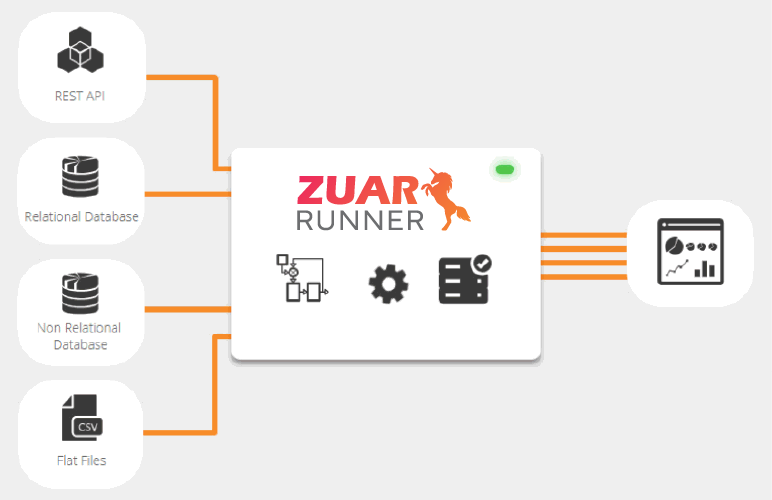
The Complete Guide to Data Staging
In this in-depth guide, Zuar explains what data staging is, why it's important, types of data staging, software staging best practices, and more.



Introduction
Most data teams rely on a process known as ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) to systematically manage and store data in a warehouse for analytic use. Data Staging is a pipeline step in which data is 'staged' or stored, often temporarily, allowing for programmatic processing and short-term data recovery. This article will discuss staging in the context of the modern cloud storage system, and the relationship between data environments and the software release lifecycle.
Depending on the transformation process, staging may take place in or outside the data warehouse. The staging location is dependent on whether data is first loaded or transformed. You can read more about the differences between ELT/ETL here. Some teams will choose to have multiple staging areas in both locations. Often times, these staging areas directly correspond with the process of retrieving data from raw source systems into a 'single source-of-truth', defining a protocol for cleansing and curating the data, and providing methods to access the data from target data services and applications.

What is Data Staging?
The basic data staging layer is an intermediate step that sits between the data’s source(s) and target(s). The staging approach allows for a number of benefits, including: testing source data, mitigating the risk of a pipeline failure, creating an audit trail, and performing complex or computationally intense transformations.
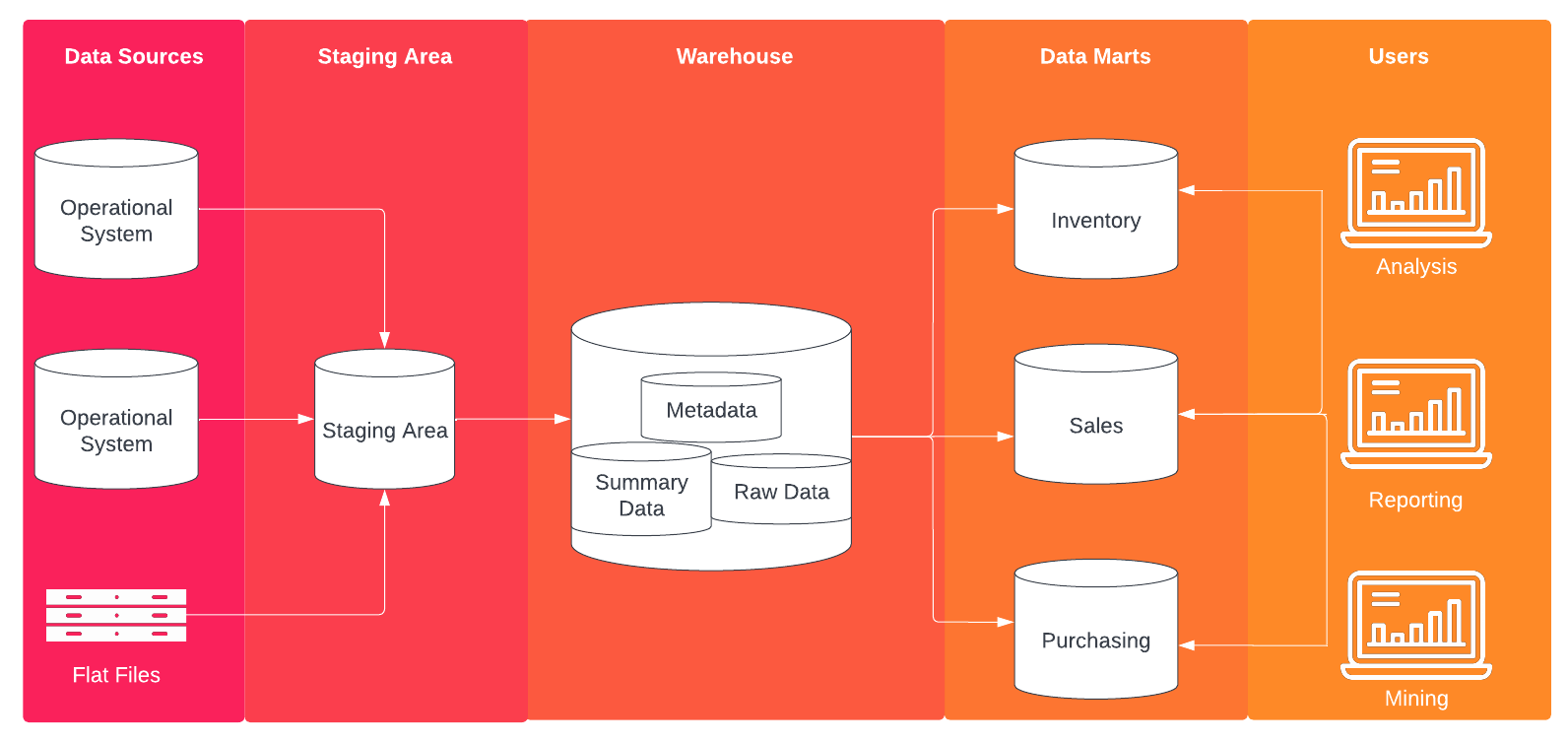
Having a single source of staged data also reduces 'data sprawl'— a term used to describe a landscape in which data is scattered (and potentially duplicated), eliminating a single source of truth. Data sprawl can lead to confused business users and analysts, degrading the impact of even well-maintained sources.
Of course, 'staging' is an inherently vague term— it can be used to describe the traditional 'staging area' for data living outside a warehouse or the more modern staging process living inside a warehouse. We’ll discuss both applications.

External Staging
The traditional data staging area lives outside a warehouse, often in a cloud storage provider, like Google Cloud Storage (GCS) or Amazon Web Simple Storage Solution (AWS S3).
In this staging process, a data engineer is responsible for loading data from external sources, collecting event streaming data, and/or performing simple transformations to clean data before it’s loaded into a warehouse.
Often, staged data is stored in a raw format, like JSON or Parquet, that’s either determined by the source or compressed and optimized specifically for staging. Amassing data in a staging area allows for future retrieval/replication of production data in the event of a failure. So long as the raw data and transformation knowledge are retained, it’s possible to fully recover any lost information. Additionally, such data records are incredibly useful for auditing purposes and serve as the foundation for data lineage management.
External staging may be useful in cases where:
- Complex transformations must be performed that are ill-suited for SQL.
- The volume of raw data exceeds that which can reasonably be stored in a data warehouse.
- Real-time or event streaming data must be transformed— engineers often need to handle late-arriving data or other edge cases.
- Operations dependent on existing data must be performed, like MERGE or UPSERT.

Internal Staging
Modern approaches to unified cloud data warehouses often utilize a separate, internal staging process. This staging involves creating raw tables, separate from the rest of the warehouse.
The raw tables are transformed, cleaned, and normalized in an 'ELT staging area'. A final layer pulls from the staging layer for 'presentation' to BI tooling and business users. By exposing only cleaned and prepared data to stakeholders, data teams can curate a single source of truth, reduce complexity, and mitigate data sprawl.
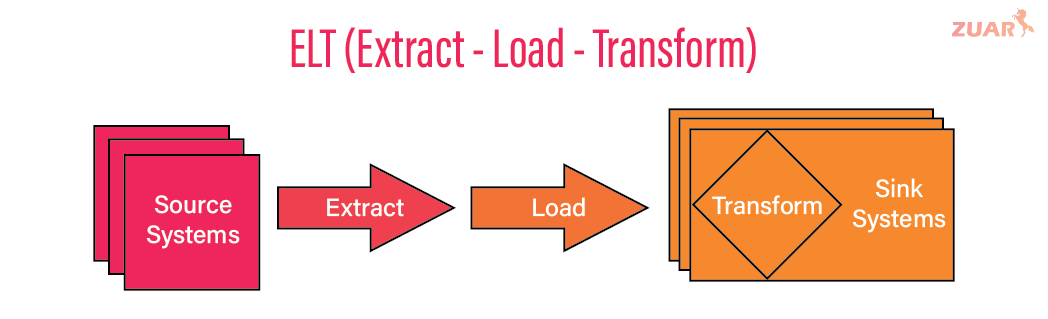
Staging tables enable indexing downstream data for quicker queries, investigating intermediate transformations (for troubleshooting, auditing, or otherwise), and potentially reusing staged data in multiple sources. The use of staging within a warehouse is the defining characteristic of an Extract, Load, Transform (ELT) process, separating it from ETL.
Staging internally allows for:
- Transforming tables that require additional information within the same dataset: analytic functions like ordering, grouping, numbering rows, running totals.
- Reducing complexity for external stakeholders and creating a 'single source of truth' for data.
- Replicating databases designed for efficiency and performance in production systems and transforming them into wide, analytic tables.
- Creating 'views' that simply apply filters to already transformed tables.
- Separating organizational data into 'marts' that can effectively serve an operational team.
- Indexing target tables for quicker re-access and queries.

Why is data staging important?
Data staging has another, broader application within a data-driven organization. It can be used to define discrete controls and access points for sensitive or error-prone data, brought in from an uncontrolled source. User-input applications, external vendors, and data referencing PII (personally identifiable information) can all be targets for strict data governance controls, all which can be accomplished with strict data staging protocols.
Consider the following setting: An organization has an ETL process which brings in data from an external source on a batch interval, and requires the data to be cleaned and processed before interacting within a warehouse-style setting.
In this process, there are key risks:
- An error within the transformation step may cancel the entire ETL operation, leading to missing data. This can be a data quality error from the source, an unhandled edge case, or an unknown factor which delays the processing of data.
- There is limited capacity to find the root cause of missing or poor quality data, as there is no way to compare raw import data to the loaded results.
- Data is only available in the processed state. If business requirements change in the future, there is a limited capability to convert the processed data back into its original form for new transformations to be applied.
These issues have an impact beyond the ETL tooling, and apply to data governance, quality, and risk practices specific to the organization. Modern data staging is used as a method to strictly apply controls to data based on a 'zone', bringing together access controls, quality and cleansing requirements, and architecture-agnostic naming conventions for data access.

Zoning Data for ETL
Depending on the size of the data, the location and type of the target resource, zoning data according to its status in the data lifecycle is key.
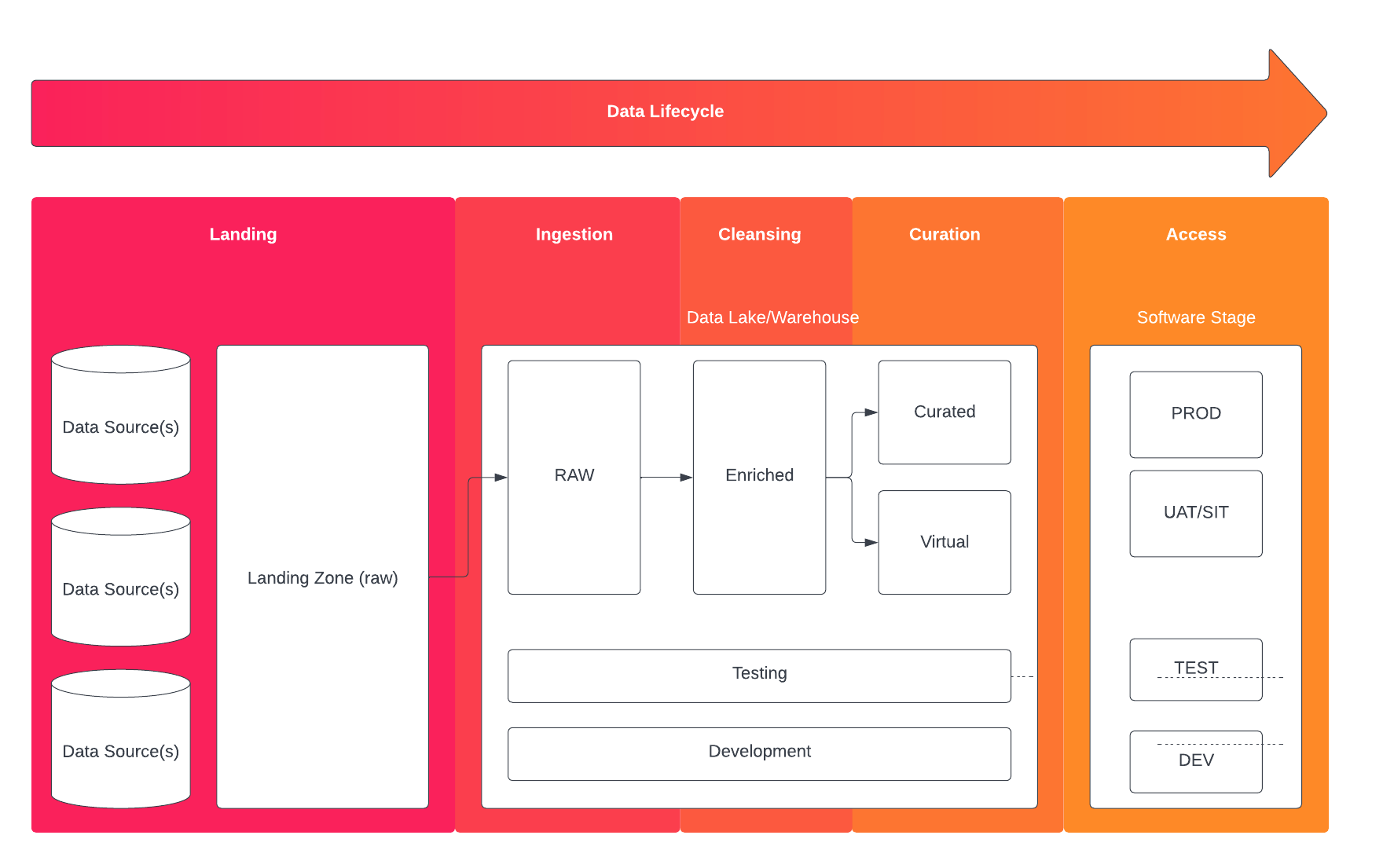
In the above depiction of a modern data lifecycle, data is separated into lifecycle 'stages': landing, ingestion, cleansing, curation, and access. In an ideal state, data is only accessed by internal ETL and metadata processes during stages 1 - 3, and exposed to consumers in stages 4 and 5. In this scenario, data transformations - primarily conducted during data curation - are only processed on clean data and therefore are guaranteed to produce clean results. An element of virtualization can be added to this process in order to allow the software clients access to facilitate their own data transformations and curations.

Access and Transformation Controls
Defining rules along these data stages is an important step in ensuring data is preserved, clean, and controlled as it transits between data stages. Key controls are often implemented to guarantee the data preservation, usually by a data quality interface. Common controls include:
- Data is not accessed in the 'landing' or 'raw' zones by external services.
- Data is not deleted, removed, or changed in the 'landing' and 'raw' zones.
- Rules engines will validate that data is in a 'clean' state in the 'enriched' zone.
- Data transformations and views are only performed in the 'curated' zone.
- Data in development and testing environments are generally consistent with production data.
These controls generally ensure that data is maintained throughout the data lifecycle, and the 'enriched' layer can generally be used as a single source-of-truth for data in the ecosystem. Once these controls are present, an organization has an efficient pipeline to processing data in a clean, effective, and controlled manner.

Software Staging Best Practices
Aligning software stages to the associated data locations is relatively easy for a modern data lake or warehouse architecture. Software environments in a data-driven architecture should directly interconnect with the associated data stages, separating development and testing data from production data. In most cases, UAT or SIT software deployments should point to production data to eliminate data quality issues in the release process.
As the standard for data lake and warehouse management has increased in scope, the data requirements for development and testing data have changed dramatically. In any case, this data should mirror production data as closely as possible. However, in a big data capacity, where the cost of production data is high, maintaining 3-5 stages and replications of this data can be a large drain on resources. For this purpose, segregating development and testing data into individual, single-stage zones has become a common practice.

Real-World Implementation
'Data Staging' is a broad term that can be used to describe a number of data processes. As it relates to the modern cloud data warehouse, data staging can be external or internal. In the former, data engineers are often handling large quantities of raw, unstructured data— perhaps from an event streaming service. In the latter, analysts are using SQL and pipeline tools to transform and curate data for business stakeholders and BI tools.
Though staging can be implemented in a number of ways, many benefits are common: an intermediate storage/processing step opens the door for testing data, building controls around data access and curation, and defining a pipeline at an organizational level to manage and control access to data at scale. By following data staging best practices, an organization can ensure data is handled with care in a clean environment, corresponding directly to software deployment stages, and that strict governance and controls are implemented to ensure optimal data security.
Data staging is just one link in the chain of a data pipeline. To complete the data pipeline and get data flowing from all sources into a centralized database, you need to transport, warehouse, transform, model, report and monitor all of your data. Thankfully, there are turn-key solutions that will do all this for you- such as Zuar's robust data pipeline solution, Runner.
Our team at Zuar will help you every step of the way in building your data pipeline from strategy formulation, to implementation, to long-term support. Take the first step and schedule a free data strategy assessment with one of our data experts: