What is Modern Data Architecture?
See what modern data architecture looks like, its pillars, cloud considerations, simplifying with an end-to-end data pipeline solution, and more!


Modern data architecture uses cutting-edge data infrastructure to deliver value at scale, using the latest in cloud computing technologies. Designed to enable seamless storage, transformation, and ingestion of big data, modern data architecture has been inspired by advancements in cloud storage and processing.
In this article, we'll discuss the importance of a robust data architecture, the components of a successful stack, and how you can approach your own implementation.

The Need for Modern Data Architecture
Data technology has rapidly evolved in the past several years. Innovations have increased the complexity of building data systems at scale: navigating data stores and lakes, analytics platforms, stream processing, and AI/data science efforts can be overwhelming.
Furthermore, a competitive landscape means that businesses must adapt or risk losing market share to more data-driven peers.
A modern data architecture is necessary on two fronts:
- Systems that support day-to-day ops for cloud-driven businesses.
- Analytic systems that power data-driven decisions through an analytics-capable infrastructure.
For companies to build a reliable application and a culture of data-driven processes, they need robust analytic and operational systems.
Modern data architecture provides solutions for both; we'll dive into the core tenets of a modern data architecture and provide some criteria for how you can think about implementing the right architecture for your team.

Pillars of Modern Data Architecture
Modern data architecture is built on the premise that large amounts of data should be stored and programmatically refined, transformed, and processed to create valuable outputs.
These outputs typically take the form of models or analyses that unlock business insights, create product functionality, or in some cases produce data that can be sold directly. To achieve this end, modern data architectures typically include:
- Data lakes: thanks to the falling cost of cloud storage, a 'big data' or data lake approach involves a cloud-based service, like AWS S3 or GCP Cloud Storage, where semi-structured data is stored en-masse. Data lakes unlock a wealth of functionality not limited to data analytics, science, and disaster recovery efforts. A properly maintained data lake will enhance data discovery while enabling big data operations.
- Databases: cloud-native databases enable everything from efficient production environments to the Modern Data Stack (MDS). From OLAP to NoSQL, there exists a range of databases that can be tailored to suit almost any need. By carefully selecting a data lake and database, your team can enable efficient data integration and storage in a cloud environment.
- Analytics: From traditional batch reporting to real-time streaming, analytics sits atop the foundation created by databases. Many newer solutions can even output analytics from semi-structured data directly from a data store. This has powered advancements in data storage and exploratory analysis. Ultimately, analytics is one of the simplest tried-and-true ways to deliver value with data.
- Science: More advanced techniques, like ML or AI-based methods, fall under the data science umbrella. Also enabled by foundational storage (lakes and databases), data science follows from analytical techniques but layers in additional tools and services, like Amazon SageMaker or Google Vertex AI.
- Governance: Valuable data starts with accurate metadata, which underlies data governance. Metadata management, data lineage, security, and regulatory compliance all fall under the umbrella of data governance. Big data can be a big liability, so it's important to have a scalable way of understanding where data lives and ensuring proper access. As data evolves, data governance might expand to include data contracts, which can enable schema evolution and improved relationships between consumers/producers in large organizations.
Of course, every data team has different needs. In practice, this means each architecture will be slightly different; some might not be ready for advanced data science techniques, instead choosing to focus on foundational analytics efforts.
Others might choose to expand on data governance, building out robust lineage systems that span the ingestion, transformation, and dissemination of data. The best solution is the one tailored to your use case.
Consider meeting with Zuar's team to help implement the most efficient solution for your needs. With our considerable experience in all things data related, we can assist you every step of the way.

Thinking Differently About Data
In today's hyper-competitive business environment, making data-driven decisions is table stakes. Data-driven counterparts will quickly out-maneuver and out-innovate those who choose to operate solely by intuition.
While intuition has a place in business, so do quantitative and qualitative research efforts. Not only is the competitive landscape shifting towards ever-greater usage of data, but the speed of software delivery is accelerating.
Many startups operate under a SaaS model, their core product being easily mutable. The recent shift towards a microservice architecture has enabled more effective CI/CD processes (continuous integration, continuous delivery) and thus more rapid development.
This has implications for data capture and reporting; our data infrastructure must flex to accommodate more fine-grained applications and bleeding-edge software architectures.
We must think differently about data to implement a modern data infrastructure, not only to remain competitive, but to support an evolving software delivery process.

A Unified Platform for Enterprise Data
For the data practitioner, choosing an appropriate platform can be daunting. Vendor lock-in, tool selection, cost, and technical debt worry many engineers and can be direct consequences of a misinformed conclusion.
Of course, a truly modern data architecture isn't possible without the help of data tooling and advancements pioneered by market leaders like AWS, GCP, Microsoft, and others.
In this section, we'll discuss the benefits of cloud environments and some relevant factors to consider when choosing a cloud service provider.
The Benefits of a Cloud Environment
Historically, there has been a choice between legacy, on-premise data platforms, and cloud solutions. Today, cloud environments provide a number of benefits over on-prem configurations, with a fraction of the up-front cost and investment.
Instead of purchasing, configuring, and deploying physical machines, identical infrastructure can be deployed in the cloud in minutes (and scaled just as quickly). Here are a few of the benefits that cloud environments provide:
- Speed: applications can be brought online in minutes with little up-front cost. Configuration is abstracted away in cloud-managed environments.
- Scalability: cloud services come with virtually infinite resources and autoscaling capability.
- Cost: Though the topic is hotly debated, there will be drastically lower up-front cost to a cloud deployment. Leveraging pricing incentives, cloud operation can be cost-effective in most implementations.
- Maintenance: cloud environments manage resources in a way that reduces the amount of maintenance necessary.
More often, the choice in modern data architecture lies in the applications that sit in the cloud. We can think about two different types of cloud-based applications: Cloud-First and Cloud-Hosted.
- Cloud-hosted: These are basically on-prem services adapted to run in the cloud. While in the cloud, configuration, scaling, and maintenance are all managed by a team of developers.
- Cloud-first: These are fully managed cloud solutions. All configuration and management is abstracted away to provide a solution that reduces complexity and allows the user to focus on functionality rather than maintenance.
Today, the choice is rarely between cloud and on-prem, but between cloud-first or cloud-hosted applications in a cloud environment (unless there are unique considerations such as highly sensitive data, where on-prem may be mandatory). Thought must be given to what cloud service providers you utilize—each has different strengths, weaknesses, and pricing structures.
When leveraged properly, the optimal cloud provider can put your engineering organization at a tremendous advantage. Of course, the opposite is also true: an uninformed choice will have drastic consequences.

Selecting a Modern Data Architecture
Data platforms are a critical choice for building data applications. Choosing a modern database is an investment in the corresponding provider, an investment in the reliability, scalability, and ultimately success of your project. While many data teams end up on platforms selected by a product or engineering org, we'll discuss some important aspects for those who have the freedom to choose.
When choosing a cloud provider, the following considerations should be given special attention:
- Relational database support: though a relatively old technology, relational databases are at the core of almost every product and data offering. Products like Postgres and MySQL still serve as production databases for many, and cloud-native data warehouses, like Redshift, Snowflake, and BigQuery, have revolutionized data science and analytics. Ensuring adequate relational database coverage is essential.
- NoSQL database support: As the size and scope of data increases, NoSQL databases (such as MongoDB) have proved critical. The ability to handle fast writes and lookups for large amounts of semi-structured data is more important now than ever. While they may not serve an analytics need, they're an important piece of technology.
- Separation of storage and compute: historically, compute and storage were intertwined: if you needed more processing power, it was necessary to scale both variables, not just one. Snowflake revolutionized the data warehousing space by separating computation and storage architectures, to deliver a product that could scale according to multiple variables. When examining a cloud provider, be sure to evaluate each product for scaling capacity. This will save time and money in the long run.
- Data sharing: regardless of your organization, there will come a time when sharing data is essential. Whether with an external organization or directly with a customer, the ability to quickly and safely share data is essential. A specific feature to check for is the ability to share fresh, up-to-date data. Data sharing will aid in integration practices and reduce friction to collaboration.
- Reliability: of course, of what value is a service if it isn't available? Particularly in SaaS, where the product is hosted on cloud infrastructure, reliability of cloud services is paramount. Most providers will have SLAs (service-level agreements) that state some threshold for performance and uptime. Carefully inspect these to determine what the provider promises, then do some research to evaluate performance against these standards. When considering reliability, be sure to also investigate disaster recovery and monitoring tools.

Implementing Modern Data Architecture
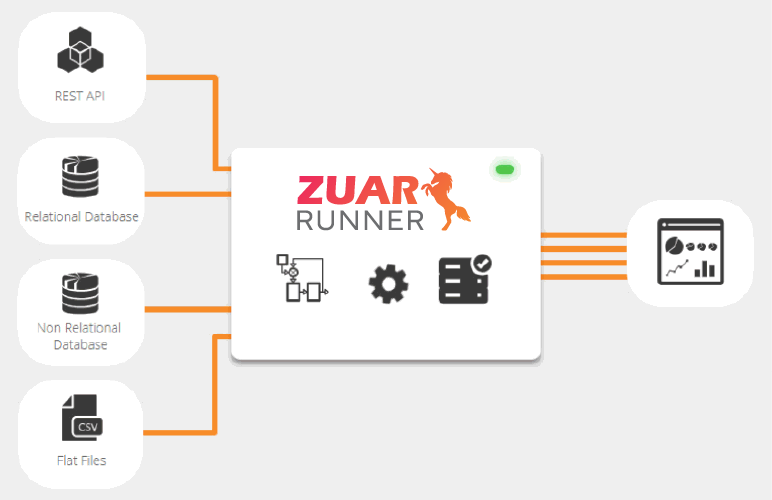
With an increasingly complex and competitive landscape, building a robust and scalable modern data architecture is critical to ensuring the success of your business. One way to simplify things is by utilizing an end-to-end data pipeline solution as part of your stack. Zuar's ELT platform Runner is a great option for this.
Zuar Runner can automate every step in your data pipelines, from ingestion to modeling to visualization. We'd love to discuss with you how this flexible solution can potentially eliminate hundreds of hours of manual processes and creating a single source of truth for all your data.
Our team of data experts is here to help you through the entire process of implementing a modern data architecture. When you're ready to get the ball rolling, contact Zuar to schedule a free data strategy assessment!