RegEx¶
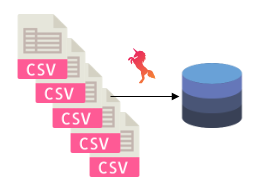
The Regex plugin creates a single “union” table in a database from any files matching a regularexpression (RegEx) by leveraging any of the flat file connectors (CSV, Excel) as a base.
See the Union plugin if you are trying to “union” multiple database tables together into single database table.
Create a RegEx job¶
Create a job using any of the flat file connectors:
Edit the job.
Input changes¶
Rename the input’s use to base. base is how the Regex plugin knows which
underlying flat file connector to use.
Add a new input use key with the value flatfile.iov2#RegexInput.
Remove the input source and add regex with the regular expression value.
SDL changes¶
If there is an sdl section, remove it entirely.
Steps changes¶
Update the steps with the job’s steps to these steps:
"steps": [
{
"column": "__mtime__",
"use": "mitto.iov2.steps#MaxTimestamp"
},
{
"use": "mitto.iov2.steps.upsert#SetUpdatedAt"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#ExtraColumnsTransform"
},
{
"use": "mitto.iov2.transform#ColumnsTransform"
}
],
"use": "mitto.iov2.steps#Input"
},
{
"use": "mitto.iov2.steps#CreateTable"
},
{
"use": "mitto.iov2.steps.upsert#CreateTempTable"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#FlattenTransform"
}
],
"use": "mitto.iov2.steps#Output"
},
{
"key": "__source__",
"use": "mitto.iov2.steps.upsert#SyncTempTable"
},
{
"use": "mitto.iov2.steps#CollectMeta"
}
]
The Regex connector uses all the input parameters (e.g. delimiter, encoding, skip, etc) from the initial job’s plugin.
Output table¶
The resulting database table has three additional columns:
__index__- the index of each row in each separate file__source__- the source file the rows originate from__mtime__- the modified time of the source file
Upsert¶
Upsert is supported for RegEx jobs by using the __source__ as the primary
key and __mtime__ as the last modified time.
Every time the RegEx job is run, it checks the output table and finds the
maximum __mtime__. Only files with modified times greater than or equal to
this __mtime__ will be upsert on each run.
If you ever need to “reset” or do a full table refresh, you can drop the output table and rerun the RegEx job.
Example¶
We have 3 CSV files we want to union together into a single database table.
Here’s what the initial CSV files look like:

Initial CSV¶
Here’s the resulting database table for regex_1.csv after using the XSV plugin:
id |
name |
index |
|---|---|---|
1 |
Justin |
1 |
And here’s the resulting database table after using the RegEx plugin:
id |
name |
index |
source |
mtime |
|---|---|---|---|---|
3 |
Birdie |
1 |
regex_3.csv |
2020-02-19 17:30:20.680760 |
2 |
Bear |
1 |
regex_2.csv |
2020-02-19 17:30:20.628760 |
1 |
Justin |
1 |
regex_1.csv |
2020-02-19 17:30:20.572761 |
Here’s the job config for the original XSV job:
{
"input": {
"delimiter": ",",
"encoding": "ASCII",
"includes_header": true,
"source": "/var/mitto/data/regex_1.csv",
"use": "xsv.iov2#XsvInput2"
},
"output": {
"dbo": "postgresql://dbo/analytics",
"schema": "test",
"tablename": "regex_1",
"use": "call:mitto.iov2.db#todb"
},
"sdl": {
"columns": [
{
"__header__": "id",
"__jpath__": "$.'id'",
"name": "id",
"type": "Boolean"
},
{
"__header__": "name",
"__jpath__": "$.'name'",
"length": 30,
"name": "name",
"type": "String"
}
],
"name": "regex_1"
},
"steps": [
{
"transforms": [
{
"use": "mitto.iov2.transform#ExtraColumnsTransform"
},
{
"use": "mitto.iov2.transform#ColumnsTransform"
}
],
"use": "mitto.iov2.steps#Input"
},
{
"use": "mitto.iov2.steps#CreateTable"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#FlattenTransform"
}
],
"use": "mitto.iov2.steps#Output"
},
{
"use": "mitto.iov2.steps#CollectMeta"
}
]
}
And here’s the modified job config using the RegEx plugin:
{
"input": {
"delimiter": ",",
"encoding": "ASCII",
"includes_header": true,
"regex": "^regex_.+\\.csv$",
"base": "xsv.iov2#XsvInput2",
"use": "flatfile.iov2#RegexInput"
},
"output": {
"dbo": "postgresql://dbo/analytics",
"schema": "test",
"tablename": "regex",
"use": "call:mitto.iov2.db#todb"
},
"steps": [
{
"column": "__mtime__",
"use": "mitto.iov2.steps#MaxTimestamp"
},
{
"use": "mitto.iov2.steps.upsert#SetUpdatedAt"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#ExtraColumnsTransform"
},
{
"use": "mitto.iov2.transform#ColumnsTransform"
}
],
"use": "mitto.iov2.steps#Input"
},
{
"use": "mitto.iov2.steps#CreateTable"
},
{
"use": "mitto.iov2.steps.upsert#CreateTempTable"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#FlattenTransform"
}
],
"use": "mitto.iov2.steps#Output"
},
{
"key": "__source__",
"use": "mitto.iov2.steps.upsert#SyncTempTable"
},
{
"use": "mitto.iov2.steps#CollectMeta"
}
]
}
The input’s use was renamed to base. A new use (for the RegEx plugin)
was added to the input. The input’s source was removed and regex was
added. The output tablename was updated. The steps were completely
replaced with the RegEx steps.
The input’s regex for this particular job is ^regex_.+\\.csv$. We are
looking for any files that start with (^) regex_, have any characters in
the middle (.+), and end with ($) .csv.
This regex will feed in the 3 files we want to union:
regex_1.csv
regex_2.csv
regex_3.csv
Regular Expression Syntax¶
One helpful tool for testing regular expressions is RegExr .
One important thing to remember, In older versions of Zuar Runner (pre-2.9.x)
because a job’s config is stored in JSON, when using escape characters (\),
you need to double escape them (\\).
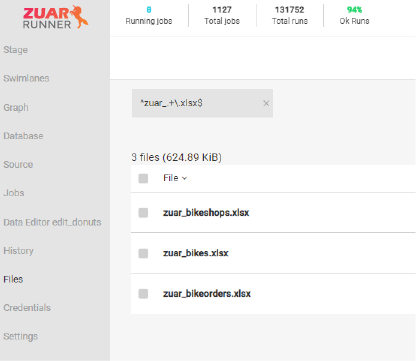
PRO-TIP: Testing in the Files Page¶
You can test what your regular expression will match by using the search input on the Files Page.