Union¶
Zuar Runner’s Union plugin combines multiple database tables into a single “union” database table.
The input tables all need to be from the same source database. However, the output database table can be a completely different database altogether.
See the RegEx plugin if you are trying to “union” multiple flat files together into a single database table.
Example Union Use Case¶
As an example, we want to take two tables that look like this:
Table A
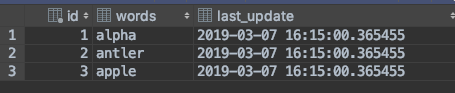
Table B

And union them together.
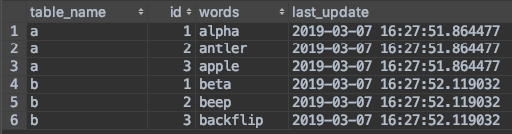
Notice the addition of the table_name column to differentiate between the rows of each table after the union.
What if the Tables Have Different Columns or Data Types?¶
Zuar Runner handles this by learning the input data as it is processed and creates the correct output union table.
Table A

Notice Table A has 4 columns: id, words, places, and last_update.
Table B:

Notice Table B is missing the places column.
Union Table
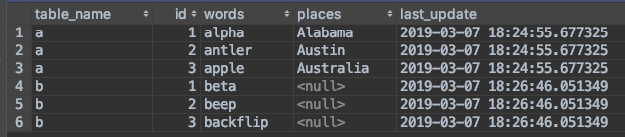
Notice the addition of the table_name column to differentiate
between the rows of each table after the union. Also notice rows
associated with Table B have NULL values for the places
column.
Create a Zuar Runner Union Job¶
Zuar Runner Union jobs are created with the Generic
plugin. The job type is io
(input/output).
Example job configuration:
{
"input": {
"dbo": "postgresql://db/analytics",
"use": "union.iov2#TableSetInput",
"last_modified_column_name": "last_update",
"source_column_name": "table_name",
"table_names": {
"example.table_a": "a",
"example.table_b": "b"
}
},
"output": {
"dbo": "postgresql://db/analytics",
"schema": "unioned",
"tablename": "tables_unioned",
"use": "call:mitto.iov2.db#todb"
},
"steps": [
{
"transforms": [
{
"use": "mitto.iov2.transform#ExtraColumnsTransform"
},
{
"use": "mitto.iov2.transform#ColumnsTransform"
}
],
"use": "mitto.iov2.steps#Input"
},
{
"use": "mitto.iov2.steps#CreateTable"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#FlattenTransform"
}
],
"use": "mitto.iov2.steps#Output"
},
{
"use": "mitto.iov2.steps#CollectMeta"
}
]
}
Union job config values:
- Input → source_column_name - This is the new column that will
appear in the “union” table. In our example above, this is how the new column
table_nameis created.
- Input → table_names - This JSON object lists the tables to be
unioned (
{schema}.{table}) and the values created for thesource_column_name‘s rows. In our example above, this is how the newtable_namecolumn is populated with values from each table (e.g.aandb).
Union with Upsert¶
Zuar Runner Union jobs can be configured to handle upsert.
Example job configuration:
{
"input": {
"dbo": "postgresql://db/analytics",
"use": "union.iov2#TableSetInput",
"last_modified_column_name": "last_update",
"source_column_name": "table_name",
"table_names": {
"example.table_a": "a",
"example.table_b": "b"
}
},
"output": {
"dbo": "postgresql://db/analytics",
"schema": "unioned",
"tablename": "tables_unioned",
"use": "call:mitto.iov2.db#todb"
},
"steps": [
{
"use": "union.iov2.steps#TimestampBySource",
"source_column_name": "table_name",
"last_modified_column_name": "last_update"
},
{
"use": "mitto.iov2.steps.upsert#SetUpdatedAt"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#ExtraColumnsTransform"
},
{
"use": "mitto.iov2.transform#ColumnsTransform"
}
],
"use": "mitto.iov2.steps#Input"
},
{
"use": "mitto.iov2.steps#CreateTable"
},
{
"use": "mitto.iov2.steps.upsert#CreateTempTable"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#FlattenTransform"
}
],
"use": "mitto.iov2.steps#Output"
},
{
"use": "mitto.iov2.steps.upsert#SyncTempTable",
"key": [
"table_name",
"id"
]
},
{
"use": "mitto.iov2.steps#CollectMeta"
}
]
}
Union job with upsert config values:
Input → source_column_name - This is the new column that will appear in the “union” table. In our example above, this is how the new column
table_nameis created.Input → table_names - This JSON object lists the tables to be unioned (
{schema}.{table}) and the values created for thesource_column_name‘s rows. In our example above, this is how the newtable_namecolumn is populated with values from each table (e.g.aandb).Input → last_modified_column_name - This is the timestamp column in the “source” tables that is used for upsert. In our example above, this is the
last_updatecolumn.Steps → source_column_name - This is the same column from the input. This column is used to determine the last modified column value per section of the union. In our example above, this column is
table_name.Steps → last_modified_column_name - This is the timestamp column used for upsert. In our example above, this column is
last_update.Steps → key - This is a JSON array listing the column(s) that uniquely identify a row in the union table. In the example above, the primary key from the source tables is
id. We also add in thetable_namecolumn value from the input. The combination of these two values is how we uniquely identify a row in the union table.